Data Lakehouse Architecture: The Foundation for AI-Driven Data Strategies
Data Lakehouse Architecture: The Foundation for AI-Driven Data Strategies
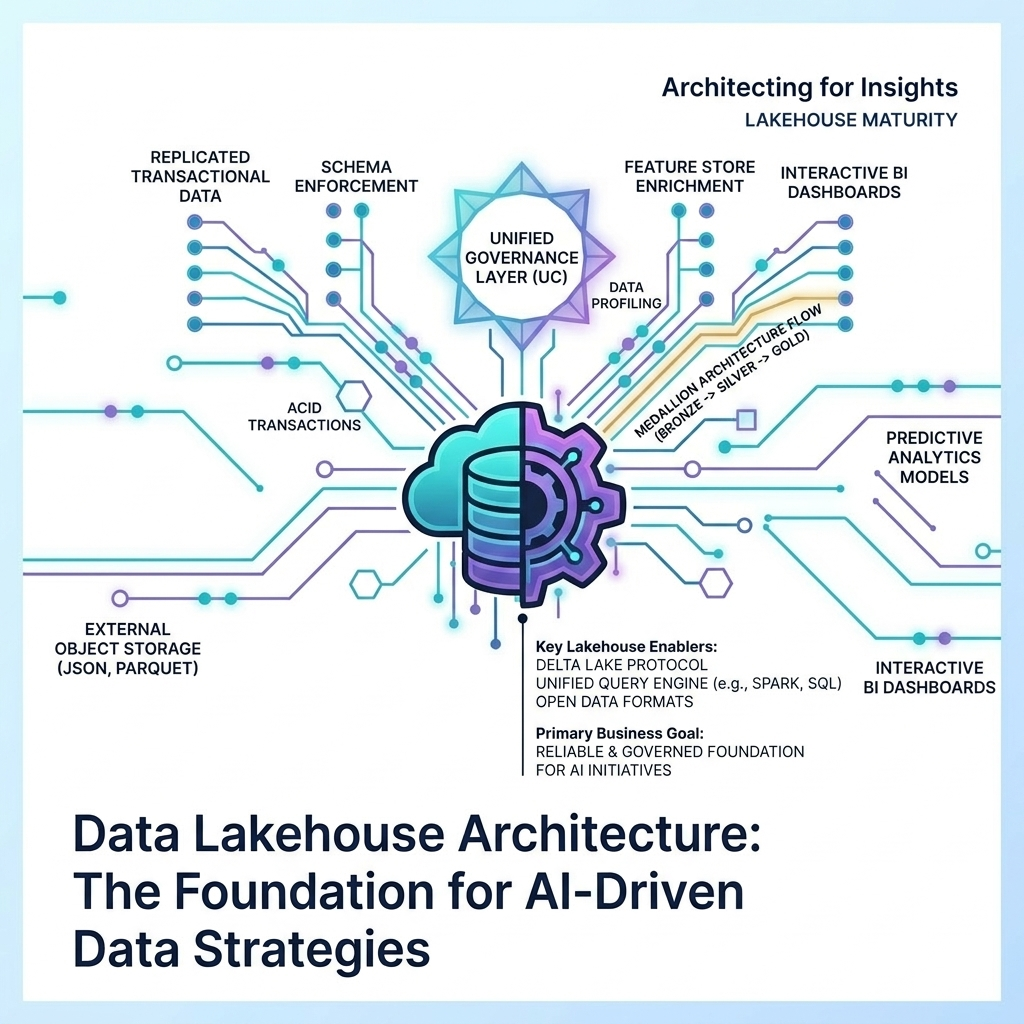
The landscape of enterprise data management has undergone a profound transformation, moving beyond the traditional dichotomy of data lakes for raw storage and data warehouses for structured analytics. Today, the Data Lakehouse Architecture has emerged as the dominant paradigm, offering a unified, flexible, and scalable foundation for AI-driven data strategies. Spearheaded by innovative technologies like Delta Lake and Apache Iceberg, this architecture bridges the best of both worlds, providing ACID (Atomicity, Consistency, Isolation, Durability) transactions on cost-effective object storage, seamlessly integrating with cutting-edge tools like vector databases, and laying the groundwork for exabyte-scale data storage and advanced analytics. This isn’t just an architectural evolution; it’s a strategic imperative for organizations aiming to unlock the full potential of their data in the age of artificial intelligence.
The Strategic Imperative: Unifying Data for AI Advantage
For organizations to truly harness the power of AI, they require a data infrastructure that is both robust and adaptable. The data lakehouse architecture fulfills this need by offering a unified approach to data management. It combines the flexibility and vast scalability of data lakes—which are ideal for storing diverse, multi-structured data at a low cost—with the critical data management features traditionally found in data warehouses, such as schema enforcement, data governance, and transactional capabilities.
This convergence is crucial for companies looking to derive advanced insights from their ever-growing and increasingly diverse datasets. It supports a spectrum of workloads, from traditional Business Intelligence (BI) and reporting to the most demanding modern AI and Machine Learning (ML) applications. By providing ACID transactions directly on cloud object storage (like AWS S3, Azure Data Lake Storage (ADLS), or Google Cloud Storage (GCS)), the lakehouse ensures data reliability and consistency. This is a non-negotiable requirement for critical business operations, where data accuracy and integrity directly impact decision-making and regulatory compliance.
Moreover, the integration with vector databases represents a significant leap forward, particularly for advanced AI applications. Vector databases are essential for enabling similarity searches, semantic understanding, and the efficient operation of RAG (Retrieval Augmented Generation) architectures for large language models (LLMs). By bringing these capabilities into the lakehouse ecosystem, organizations can build more sophisticated, context-aware AI applications that can reason over and generate insights from massive, multi-modal datasets, transforming how businesses interact with information.
Technical Architecture: A Layered System for Scalable Innovation
At its technical core, the data lakehouse architecture is a layered system built upon cloud object storage, providing a cost-effective and highly durable foundation for exabyte-scale data. On top of this storage layer reside open table formats such as Delta Lake, Apache Iceberg, and Apache Hudi. These formats are the unsung heroes of the lakehouse, delivering the crucial capabilities that elevate object storage to a transactional data platform.
These open table formats provide:
- ACID Transactions: Ensuring data integrity and consistency for concurrent read/write operations.
- Schema Evolution: Allowing data schemas to change over time without breaking existing applications.
- Time Travel: Enabling users to access and query historical versions of data, crucial for auditing, reproducibility, and recovering from errors.
- Intelligent Pruning: Optimizing query performance by efficiently filtering data at the file level.
These formats meticulously track files and snapshots, providing the transactional guarantees that were once exclusively the domain of expensive, proprietary data warehouses. Delta Lake’s UniForm (Universal Format) further enhances interoperability, allowing Delta tables to be read by clients of other open formats like Iceberg and Hudi. This fosters an open, flexible ecosystem, mitigating vendor lock-in and promoting innovation.
The architecture typically includes a robust ingestion layer designed to handle both batch and streaming data processing, enabling real-time analytics and ensuring that the lakehouse always contains the freshest possible data. A sophisticated catalog layer, often integrated with tools like Databricks Unity Catalog, is essential for centralized governance, metadata management, and the discoverability of data assets across the entire organization.
Finally, a flexible consumption layer serves a diverse array of workloads with consistent semantics. This includes SQL queries for traditional BI tools, interactive dashboards, notebooks for data science and ML experimentation, and direct interfaces for AI agents. The seamless integration with vector databases, such as Pinecone, Milvus, or Weaviate, is becoming a standard pattern for AI applications, enabling efficient similarity search and RAG operations directly within the lakehouse environment.
Real-World Adoption and Overcoming Challenges
The widespread adoption and continuous development of open-source projects like Delta Lake, Apache Iceberg, and Apache Hudi—backed by major cloud providers and data companies like Databricks, Snowflake, Google BigQuery, Athena, and Redshift—underscore their proven practical application and success in real-world scenarios. The rapid maturation of these technologies has solidified the data lakehouse as a practical reference architecture, particularly evidenced by its use in petabyte and exabyte-scale implementations across various industries.
However, implementing a data lakehouse architecture is not without its challenges. Managing the complexity of integrating diverse components—from object storage and table formats to ingestion engines, catalogs, compute engines, and vector databases—requires robust orchestration and a clear architectural vision. Ensuring consistent data quality and governance across an evolving, vast data landscape is a continuous effort, addressed by features like schema enforcement, data quality monitoring, and centralized catalogs.
The evolving landscape of open table formats and their interoperability, particularly with innovations like UniForm, aims to mitigate vendor lock-in and foster greater flexibility. While managing multiple formats can introduce a degree of complexity, the benefits of openness and choice often outweigh these concerns. Performance optimization for exabyte-scale queries and demanding AI workloads remains a critical area, requiring careful design and continuous tuning of the entire data stack.
The “layered system” approach of the data lakehouse is poised to become even more modular and adaptable, allowing organizations to tailor their data infrastructure precisely to their evolving business needs and technological advancements. This flexibility, coupled with its inherent scalability and ability to support both traditional analytics and cutting-edge AI, cements the data lakehouse architecture as the indispensable foundation for any truly AI-driven enterprise.