The Engineering-Led Architect: Performance Optimization—Curing Bottlenecks in the Modern Data Lakehouse
The Engineering-Led Architect
Performance Optimization—Curing Bottlenecks in the Modern Data Lakehouse
In this series, we have covered the intricacies of historical tracking (SCD logic) and the physical realities of Star Schema design. But what happens when your data models are pristine, your logic is sound, yet your data platform still misses its morning SLAs?
Performance optimization is often misunderstood as purely a coding exercise—adding an index here, tweaking a WHERE clause there. While query optimization is critical, true performance breakthroughs come from an architectural perspective. A Senior Data Architect must be able to identify bottlenecks caused by poor high-level pipeline design just as easily as they can read a Spark execution plan.
Over my 13+ years of enterprise data architecture, I have found that performance issues almost always fall into one of two categories: Macro-Level Flow constraints and Micro-Level Modeling/Query constraints. Here is how I approach solving both.
The Macro-Level: Fixing Poor High-Level Design
Sometimes, the code isn’t the problem; the traffic control is the problem.
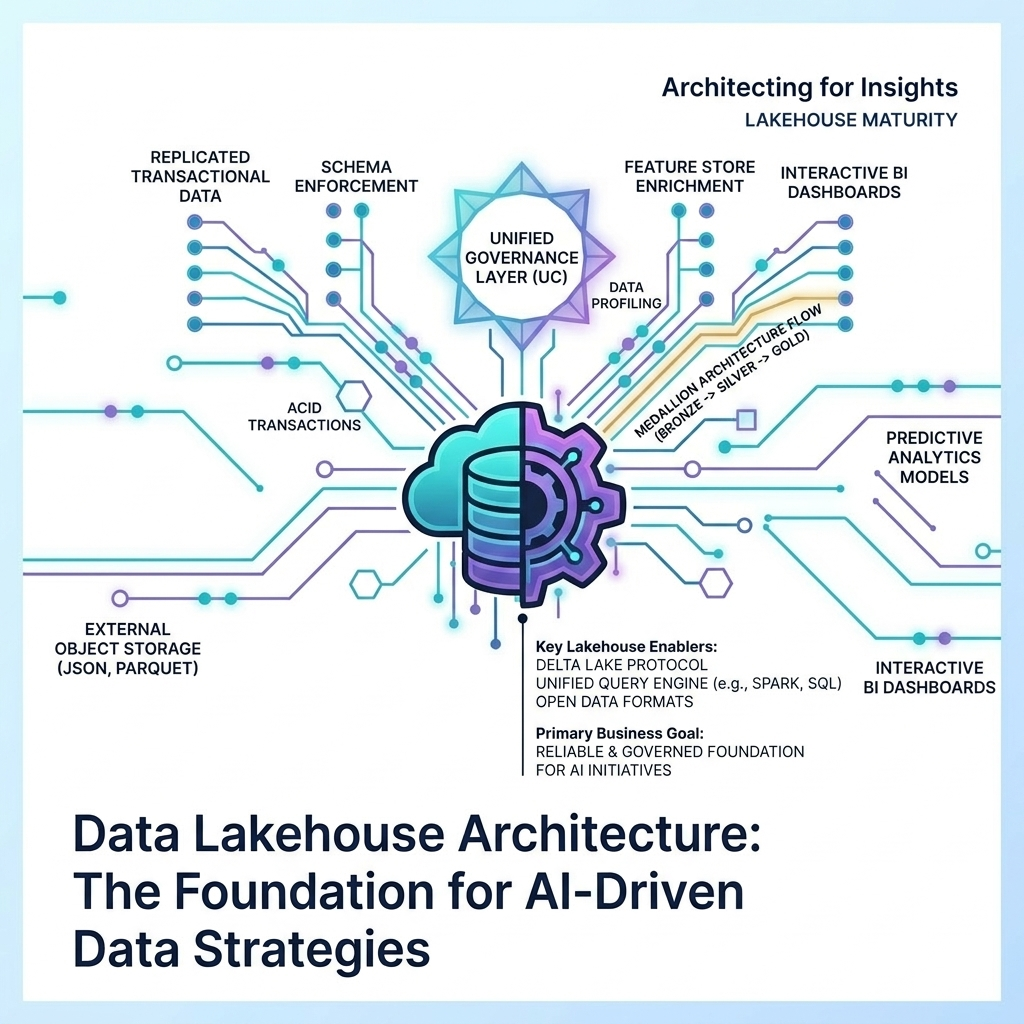
I was recently brought in to rescue a massive, 200+ table Medallion architecture load process. The business was failing to meet its 8:00 AM SLA for executive reporting. The Bronze and Silver layers were struggling to process delta records. Because the legacy Oracle source system allowed hard deletes, we couldn’t rely on simple watermark column extracts; entire multi-gigabyte tables (some containing millions of extremely wide records) had to be ingested into Silver for full-table comparisons.
To complicate matters, introducing a Change Data Capture (CDC) tool like Oracle GoldenGate was not an option due to legacy infrastructure constraints.
Identifying the True Bottleneck
When I audited the process, I didn’t immediately rewrite their SQL. I looked at the orchestration.
The pipeline was designed synchronously. Due to integration server constraints, they were extracting five tables at a time. The orchestrator would extract five tables from Oracle to Bronze, and then immediately trigger the Silver layer transformations on Databricks for those five tables.
The fatal flaw: The orchestrator waited for the Databricks Silver load to finish before extracting the next five tables.
The integration server (the bottleneck) sat completely idle while Databricks (a highly scalable distributed compute engine) did the Silver processing. They were starving their own pipeline.
The Architectural Fix: Decoupling the Flow
I remodeled the orchestration without changing a single line of underlying transformation code or altering the physical data models.
I implemented an asynchronous, decoupled queue pattern. The integration server’s only job was to continuously extract five tables at a time. As soon as one table finished extracting to Bronze, it immediately handed a token off to a Databricks workflow waiting in the cloud, and the integration server instantly grabbed the next table in the queue to extract.
At all times, the integration server was running at 100% capacity (five active extracts), while Databricks effortlessly scaled its clusters to handle the incoming Silver transformations in parallel.
The Result: The entire Bronze/Silver load process plummeted from an agonizing 6 to 8 hours daily down to just 1.5 to 2.5 hours. No table optimization, no code changes, no underlying architecture overhauls—just a fundamental correction of the high-level data flow.
The Micro-Level: Data Modeling and Query Optimization
Once the macro-level flow is decoupled and humming, you can turn your attention to the Gold layer, where data modeling and query execution plans dictate performance.
In that same project, the Gold layer processing was taking 3.5 to 4 hours on its own. While the pipeline orchestration was fixed, the actual Spark compute was thrashing. I implemented several targeted optimizations to bring that time down to roughly 2 hours.
Eradicating Redundant MERGE Statements
In a Delta Lake/Databricks environment, MERGE statements are powerful but computationally expensive because they require scanning the target table, rewriting files, and updating the transaction log.
I found processes that were executing multiple MERGE statements against the same target table within a single run (e.g., merging new inserts, then running a separate merge to update SCD Type 2 expirations). I refactored these into single, unified MERGE operations utilizing complex WHEN MATCHED and WHEN NOT MATCHED clauses. Halving the number of target table scans yielded massive I/O savings.
Strategic Caching and DAG Optimization
In complex Gold layer transformations, intermediate datasets are often referenced multiple times (e.g., joining a staging table to three different dimension tables). I optimized the Spark Directed Acyclic Graphs (DAGs) by strategically injecting df.cache() for DataFrames that were reused across multiple downstream actions. This prevented the cluster from recalculating the source extraction and initial transformations multiple times.
Furthermore, I migrated their legacy, disjointed job triggers into unified Databricks Workflows. By enforcing proper task dependencies within a single Workflow DAG, we eliminated cluster start-up overhead and allowed Databricks to intelligently share compute resources across tasks.
Partitioning and Z-Ordering
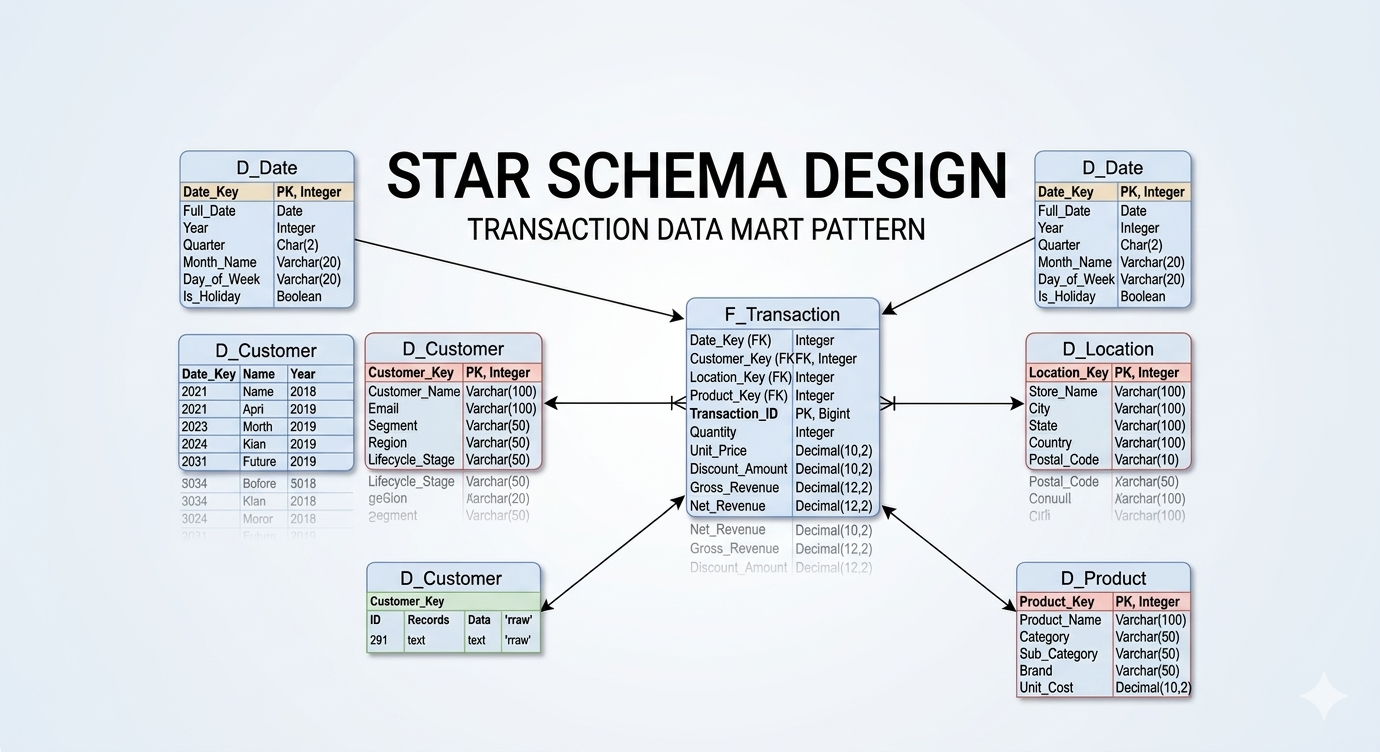
As I discussed in my previous post on Star Schemas, a model that looks perfect on paper can fail in production if the physical layout on disk is ignored.
For the largest Fact tables, query optimization requires aggressive partition pruning. However, over-partitioning can lead to the “small file problem” in cloud storage. We established a strict partitioning strategy based on the Month_ID, ensuring file sizes remained optimal. For high-cardinality columns frequently used in WHERE clauses by the BI layer (like Client_ID), we implemented Z-Ordering (multi-dimensional clustering) on the Delta tables. This allowed the Databricks engine to skip massive amounts of irrelevant data files during query execution, directly accelerating the final reporting dashboards.
Conclusion:
The Holistic View\n\nOptimizing a modern data platform is a balancing act. If your Gold layer models are bloated with redundant strings, your queries will crawl. If your MERGE statements are poorly written, your clusters will burn unnecessary compute credits. But even with perfect code and perfect models, a synchronous, poorly designed ingestion pipeline will cause you to miss your SLAs.\n\nA successful Data Architect doesn’t just write SQL; they design the entire ecosystem. They ensure the data flows smoothly from the source, lands cleanly in the Lakehouse, and is modeled aggressively for the exact realities of the consumption layer. By optimizing both the macro-flow and the micro-code, we ultimately gave the business its data back before 8:00 AM every single day.